Tech भारत: 'गूगल सर्च' कसे काम करते?



गूगलला कसे कळते कोणती वेबसाईट कुठे आहे, नवीन आलेली साईट देखील गूगल शोधून काढते? यामागे असे कोणते तंत्र आहे की, जगातल्या कोणत्याही प्रश्नांचे उत्तर गूगल देऊ शकतो?
आपल्या रोजच्या जीवनात प्रत्येक शंकेचं समाधान करणारा, पत्ता(लोकेशन) सापडवून देणारा, कुठल्याही मुव्हीची गाणी एका क्लिकवर उपलब्ध करून देणारा, सर्वात चांगले जेवण आमक्या ठिकाणी कुठे मिळेल, एखाद्या मुव्हीला किती रेटिंग आहे, या सर्व गोष्टी केवळ एका क्लिकवर उपलब्ध करून देणारे गूगल हे सर्व कसे करू शकते? असा विचार आपण केला आहे का? किंवा याचे उत्तर जाणून घेण्यात आपल्याला रस आहे का? कारण विचार करणे हे जिवंत माणसाचे लक्षण आहे, त्यामुळे याचे उत्तर आपण नक्कीच जाणून घेतले पाहिजे.
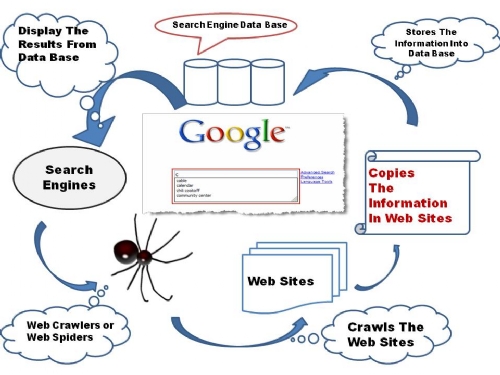
गूगल हे जगातील सर्वात जास्त वापरले जाणारे सर्च इंजिन आहे. सर्च इंजिन म्हणजे एखाद्या प्रश्नाचे उत्तर शोधण्याचे सॉफ्टवेअर. या सर्च इंजिनने जीवन जगण्याची पद्धतीच बदलून टाकली आहे. त्यामुळे सर्च इंजिनचा शोध हा इंटरनेट जगतातील क्रांतिकारक शोध मनाला जातो. याच्यामुळे सगळ्याच गोष्टी मानवाच्या बोटावर येऊन ठेपल्या आहेत. गूगलवर मिळणाऱ्या प्रत्येक माहितीचे रहस्य केवळ तीन विभागांमध्ये दडले आहे. क्रोलिंग, इंडेक्सिंग, आणि रिझल्ट.
क्रोलिंग (माहिती जमवण्याची पद्धती)
क्रोलिंग हा गूगल सर्च मधला सर्वात महत्वाचा भाग मनाला जातो. आपला एखादा प्रश्न गूगलला विचारल्यानंतर एका सेकंदाच्या आत काही लाख उत्तरे आपल्या समोर गूगल ठेवत असतो. ही क्रिया एका विशिष्ट प्रोग्रामिंगद्वारे ठरवली जात असते. त्यातील पहिली पायरी आहे क्रोलिंग.
समजायल खूप अवघड होतंय का? खूप सोप्प आहे, क्रोलिंग म्हणजे आपल्या माहिती कोषातील माहिती शोधायला लागण्याची प्रक्रिया. गूगलकडे प्रचंड माहिती साठवून आहे, ती माहिती नाव, शीर्षक, की-वर्ड्स यांच्याद्वारे शोधली जाते. संबंधित प्रश्नाशी निगडीत सर्व नावे यात शोधली जातात. यात कोळ्याच्या जाळ्याप्रमाणे एकमेकांशी निगडीत सगळे वेबपेज 'स्पायडर' नावाच्या संगणक प्रोग्रामद्वारे मिळवले जाऊन एकत्रित केले जातात. याला 'स्वयंचलित गूगल बोट' म्हणून देखील संबोधले जाते.
इंटरनेट जगतात संबंधित असलेली सगळी माहिती गूगल बोट जमा करत असताना, त्याच्या सोबत जमा झालेल्या माहितीसोबत निगडीत माहिती देखील आपोआप जमा होत असते. एखादे प्रश्न आधी विचारले असता आपल्या ब्राउझरमध्ये ती माहिती साठवलेली असते, त्यामुळे त्याचा देखील वापर गूगल बोट करत असते.
स्पायडर
इंडेक्सिंग (सूचीबद्धता)
एकदा संपूर्ण क्रोलिंग क्रिया संपल्यानंतर गूगल बोट आपली माहिती भरून आणते, त्याचे वितरण युझर्सना देण्यापूर्वी गूगल इंडेक्सिंग म्हणजेच आलेल्या माहितीची सूची लावण्याचे काम करते. एखाद्या पुस्तकात जसे अनुक्रमणिका काम करते, त्यामुळे आपल्याला एखादा मुद्दा पटकन शोधायला मदत होते, किंवा एखाद्या ग्रंथालयात अनेक पुस्तके शोधण्याचे काम जसे होते, त्याच प्रमाणे इंडेक्सिंग येथे काम करत असते. परंतु फरक एवढाच आहे की, पुस्तकातल्या मुद्द्यांचे आपण स्वत: वर्गीकरण करतो, येथे त्यासाठी प्रोग्रामिंग केलेली असते. गूगल बोटने येणारी माहिती, संगणक जगतात 'पेटा बाईट' या एककाने मोजली जाते. पेटा बाईट हे टेरा बाईटपेक्षा हजार पटीने जास्त आहे.(१ पेटा बाईट = १०२४ टेरा बाईट) केवळ एका प्रश्नाच्या उत्तरासाठी पेटा बाईट डेटा असेल तर आपण अंदाज लावू शकता कि रोज जगभरातून विचारल्या जाणाऱ्या कोटी प्रश्नांसाठी गूगलचे स्टोरेज किती मोठे असेल.

इंडेक्सिंग
रँकिंग आणि रिझल्ट
सगळ्या माहितीची सूची लावली गेल्यानंतर गूगल प्रत्येक वेबपेजची क्रमवारी म्हणजेच रँकिंग ठरवत असते. या क्रमवारी पद्धतीत ठरते की अधिकाधिक संबंधित माहिती युझर्सला दिली जावी. असंबंध माहिती याच क्रियेत वगळली जाते, आणि युझर्स समोर त्याच्या प्रश्नांचे उत्तर येते. ही सगळी क्रिया घडायला केवळ काही सेकंदांचा कालावधी लागतो.
कोणतेही सॉफ्टवेअर विशिष्ट अल्गोरिदमच्या सहाय्याने चालत असते. ते अल्गोरिदम म्हणजे त्या सॉफ्टवेअरचे सूत्र असते. जसे गणित सोडवायला आपण विविध सूत्रांचा वापर करतो, त्याच पद्धतीने सॉफ्टवेअर देखील आपले काम करायला अल्गोरिदम वापरतात, आणि त्याच्या सहाय्याने प्रत्येक समस्येवर उपाय देतात.
त्यामुळे आज आपल्याला गूगलला सर्व प्रश्नांची उत्तरे माहिती असण्याचे रहस्य माहिती पडले आहे. आता जेव्हा जेव्हा गूगलला कोणताही प्रश्न विचाराल तेव्हा उत्तर येण्याआधी सेकंद भरात किती क्रिया होता याचा अंदाज आपल्याला नक्की येईल. तसेच कुणी विचारले की गूगलला सगळे कसे माहितीये? याचे उत्तर देखील आपण देऊ शकाल. पुढच्या लेखात तंत्रज्ञानाच्या नवीन माहिती सह भेटूया. आपण Tech भारत वाचत रहा, तंत्रज्ञानात अपडेट रहा....
- हर्षल कंसारा

हर्षल कंसारा
माहिती तंत्रज्ञानातून अभियांत्रिकी पदवीधर, वेब अॅप्लिकेशन डेव्हलपमेंट क्षेत्रात कामाचा अनुभव, सॉफ्टवेअर बरोबरच लेखनात ही विशेष आवड, ब्लॉग लेखन, चालू घडामोडी, राजकारण, सामाजिक आणि तरुणाईशी संबंधित विषयांवर लिखाणाची आवड, मराठी बरोबरच गुजराती आणि इंग्रजी साहित्यात देखील रुची, रा.स्व. संघाचे स्वयंसेवक.